Data Scientist | Data Analyst
About Me
- An accomplished Data Scientist, I bring over three years of specialised experience, underscored by a Master of Data Science with Distinction from the University of Greenwich. Building strong relational databases and implementing advanced machine-learning models are two of my areas of expertise. I am skilled at turning complex datasets into useful insights using various cutting-edge technologies, including Python, SQL, Tableau, PowerBi, and Excel. I’m seeking a position as a data analyst and I am excited to put my broad skill set to use guiding creative projects and navigating complex business obstacles. My dedication is to use data to inform strategic choices and produce observable outcomes.
Projects
1. Predicting Business Success Using Machine Learning and Data Analysis
- This project aims to develop a Machine Learning model that predicts the success of startups accros the world. The prediction is based on various features including total funding received, location, and funding rounds. The model was developed after an extensive review of existing literature discussing the factors influencing startup success and the role of Machine Learning in business predictions.
Data
- The data for this project was collected from a public dataset on Kaggle. The “Big Start-up Success/Fail Dataset from Crunchbase” is a comprehensive database containing a variety of statistics about start-ups around the world. The dataset, which has 66,368 entries total across 14 variables, offers a wealth of information for study and analysis.
Methodology
- The project involved a series of steps:
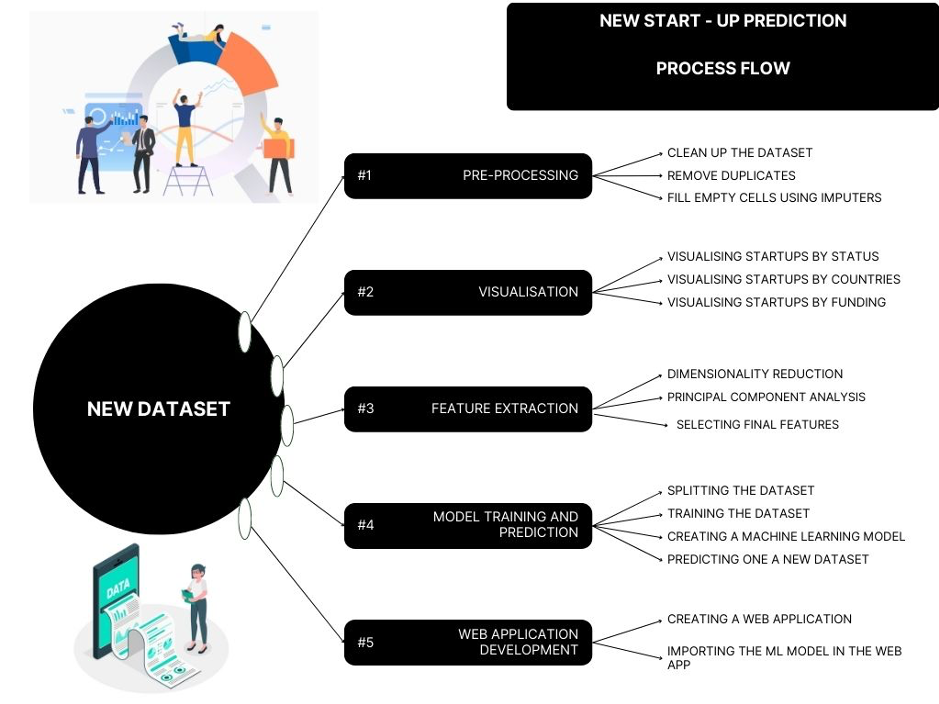
Analysis and Visualisation
-
In Order to better understand the dataset, Analysis where carried out on the data and important insights were discovered. Below is a dashboard showing the visualisations found in Tableau:
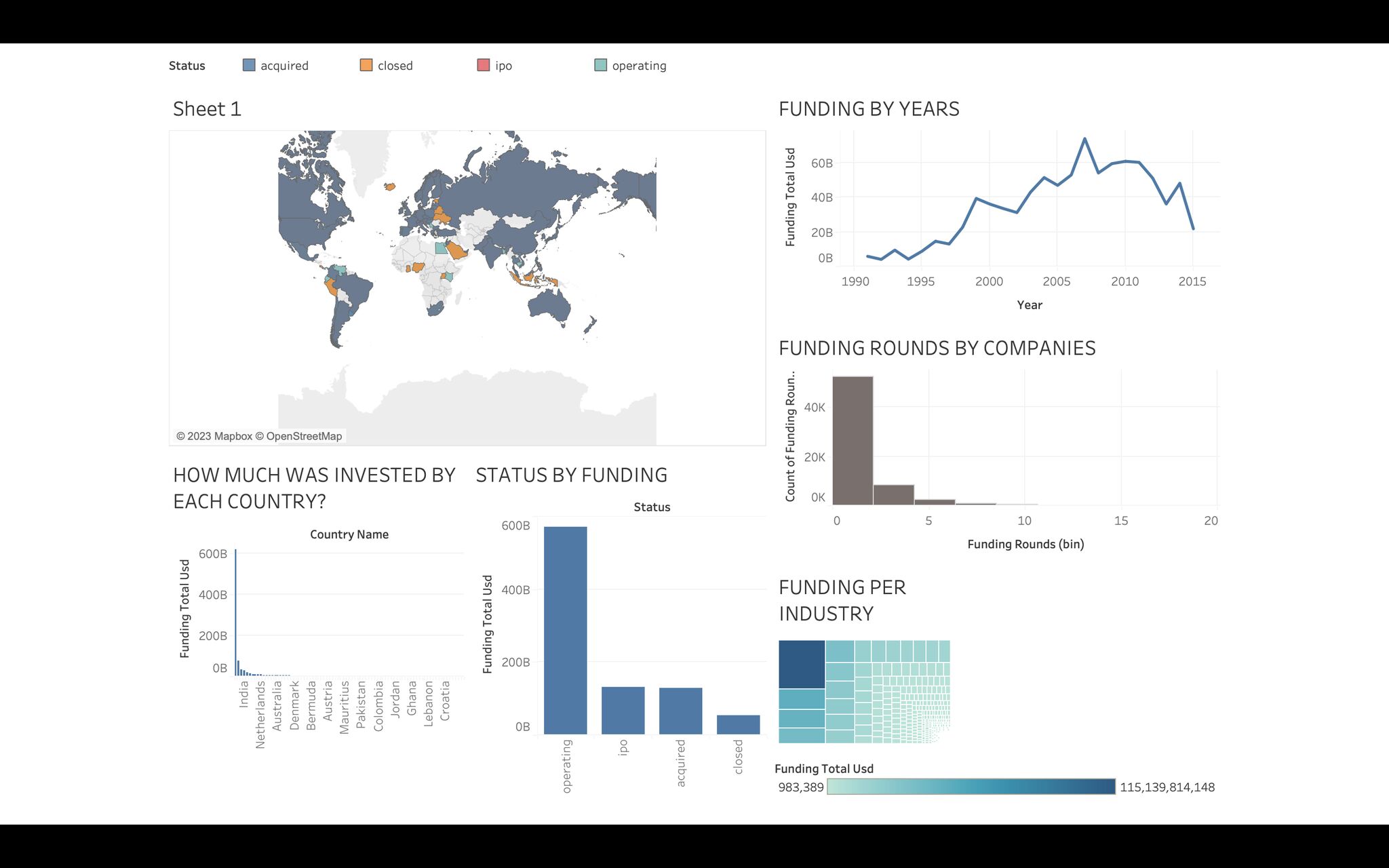
Result
- The trained model was integrated into a user-friendly web application using Streamlit to help various stakeholders in making data-driven decisions, thus reducing the risks associated with startup investments and contributing to the growth of a successful startup ecosystem.
2. 2016 Wind Industry Health and Safety Incident Analysis
- This project contains data, analysis scripts, and visualisations for health and safety incidents that occurred in the wind industry during 2016 within the UK and EU. The project’s goal is to uncover patterns, understand risk factors, and enhance safety standards within the industry.
Data
- The dataset comprises recorded incidents from the wind industry in the year 2016, capturing various aspects such as incident type, severity, and outcomes.
Methodology
Data Preprocessing
- Tool Used: Python
- Description: Raw data was cleaned and preprocessed using Python to ensure consistency and prepare it for analysis. This involved handling missing values, standardizing date formats, and categorizing incidents.
Data Analysis
- Tool Used: SQL
- Description: Using SQL, the preprocessed data was analyzed to extract insights. The analysis focused on identifying incident trends, common types of incidents, and their potential for causing harm.
Data Visualization
- Tool Used: Power BI
- Description: Interactive dashboards and visualizations were created in Power BI, providing an intuitive representation of the analysis results.
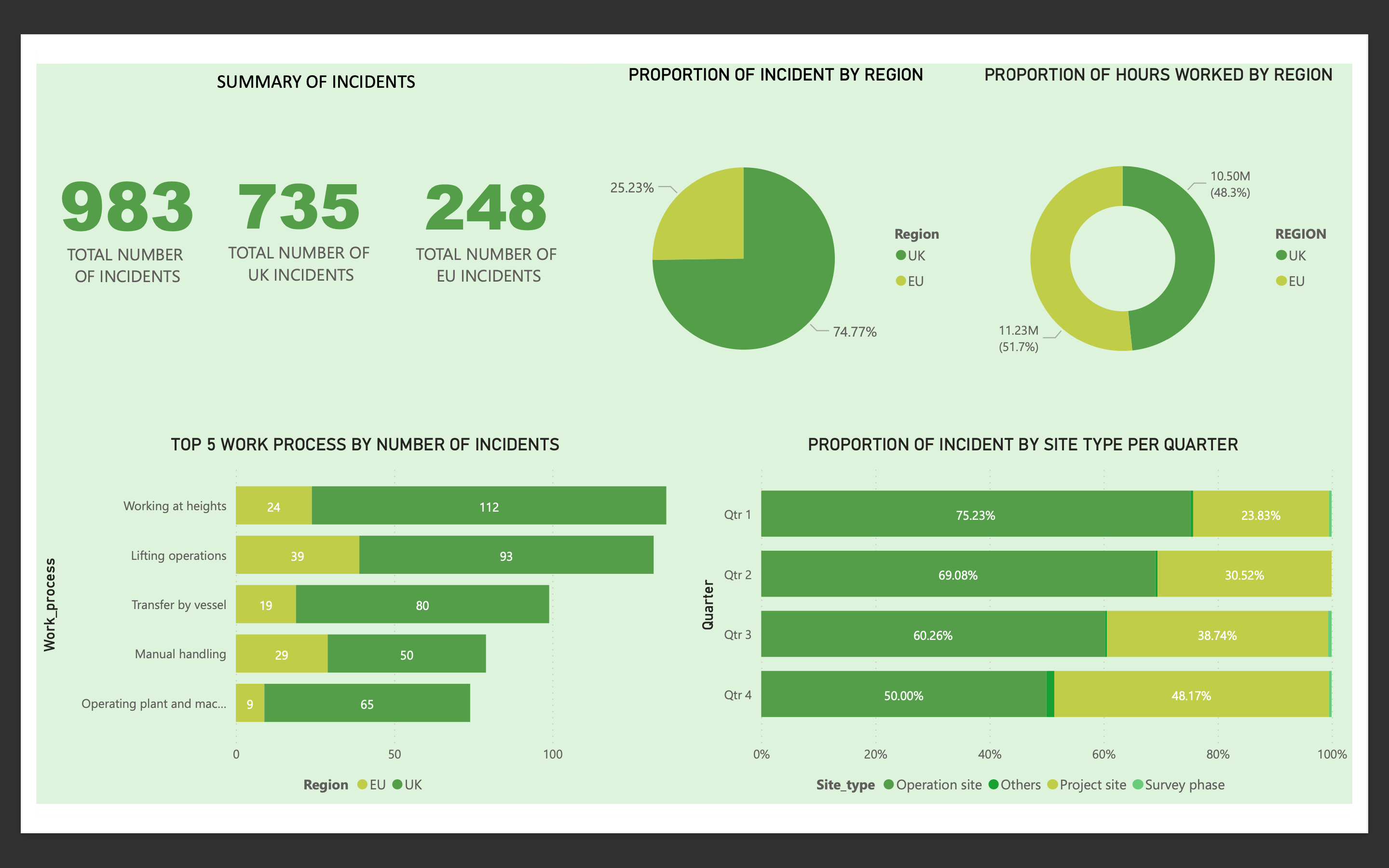
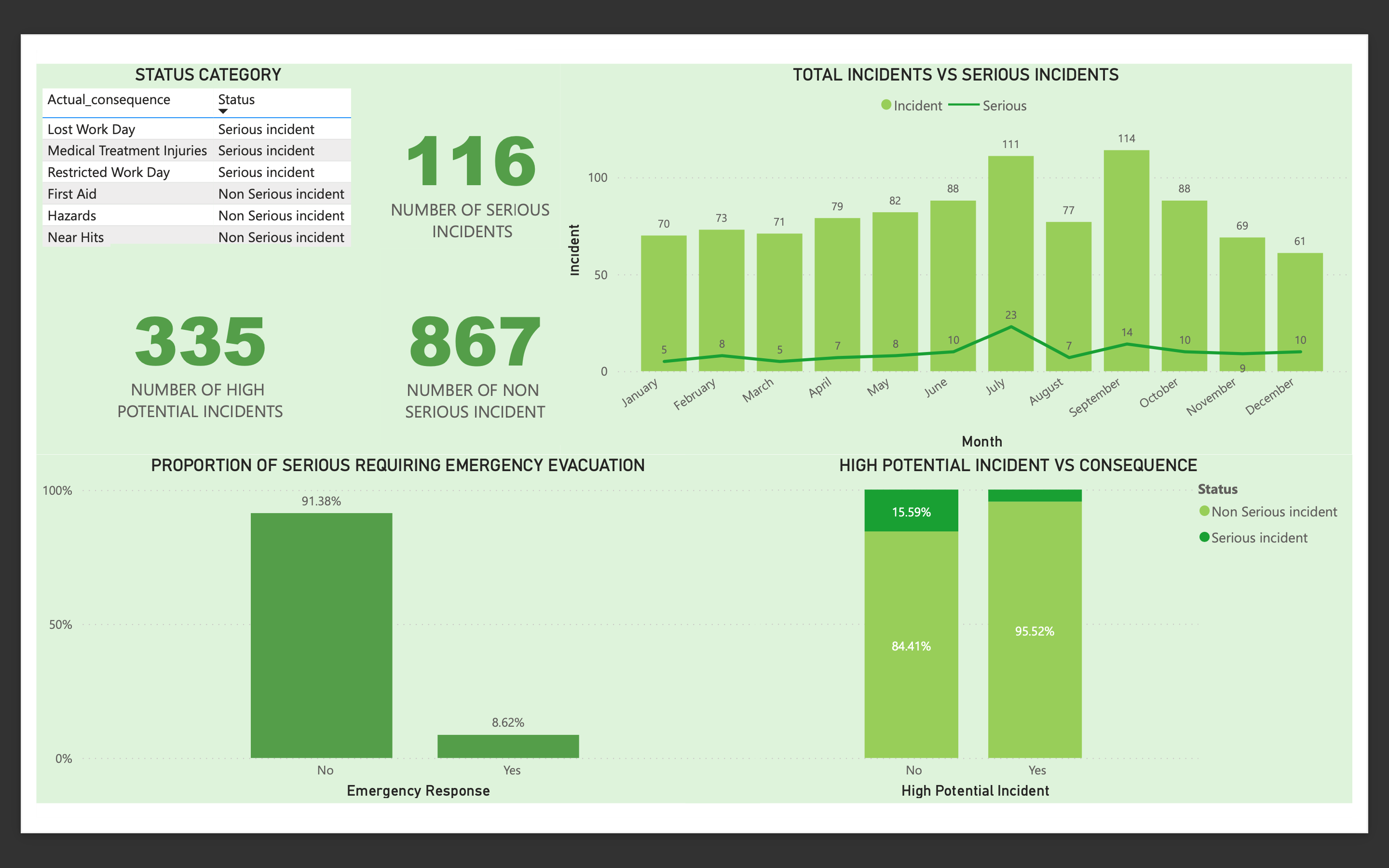
Result
-
From the above dashboard, the UK is seen to have much more incidents than the EU, even though they worked less hours that year. We also see a difference in the work processes that resulted in the most incidents.
-
Out of the 983 incidents in 2016, 11.8% resulted in a serious consequence. However only 10 ( 1% of total incidents) required emergency medical evacuation. There were also no fatalities that year.
-
In terms of the potential of a incident occuring, 16% of incidents that were marked as NOT having a high potential actually resulted in serious injuries.
3. PREDICTING THE SEVERITY OF ROAD ACCIDENTS IN THE UK
- This project aims to predict accident severity using traditional machine learning algorithms and neural networks. The dataset used in this project is derived from the UK Department for Transport, consisting of road accidents in the UK from 2005 to 2014.
Overview
-
This project consists of four main parts:
- Data Preprocessing
- Classification using Traditional Machine Learning
- Classification using Neural Networks
- Model Evaluation and Comparison
Data Preprocessing
- Data preprocessing involved cleaning and preparing the data for analysis. The main steps involved were:
- Data cleaning: removing duplicates, handling missing values, and correcting inconsistencies.
- Feature engineering: creating new features and transforming existing ones to improve model performance.
- Data splitting: dividing the dataset into training and testing sets.
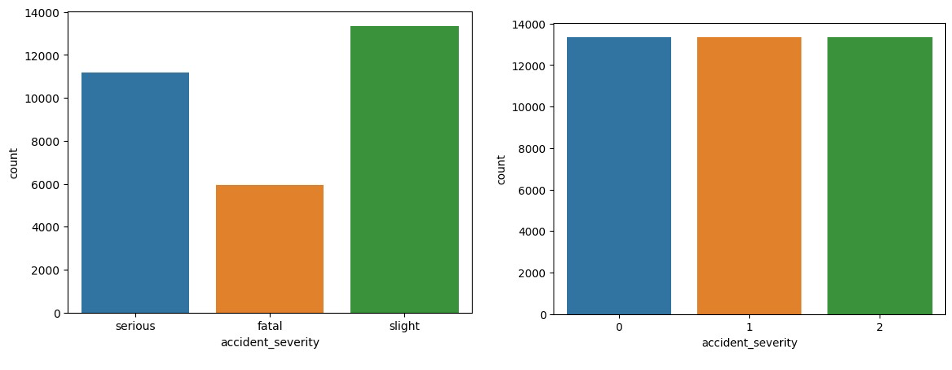
- Over Sampling: Oversampling method was used to balance the distribution of the target variable in the training set. Synthetic Minority Over-sampling Technique (SMOTE) is used to resolve any class imbalances in the dataset.
This action helps the model perform better when applied to underrepresented classes.
Classification using Traditional Machine Learning
-
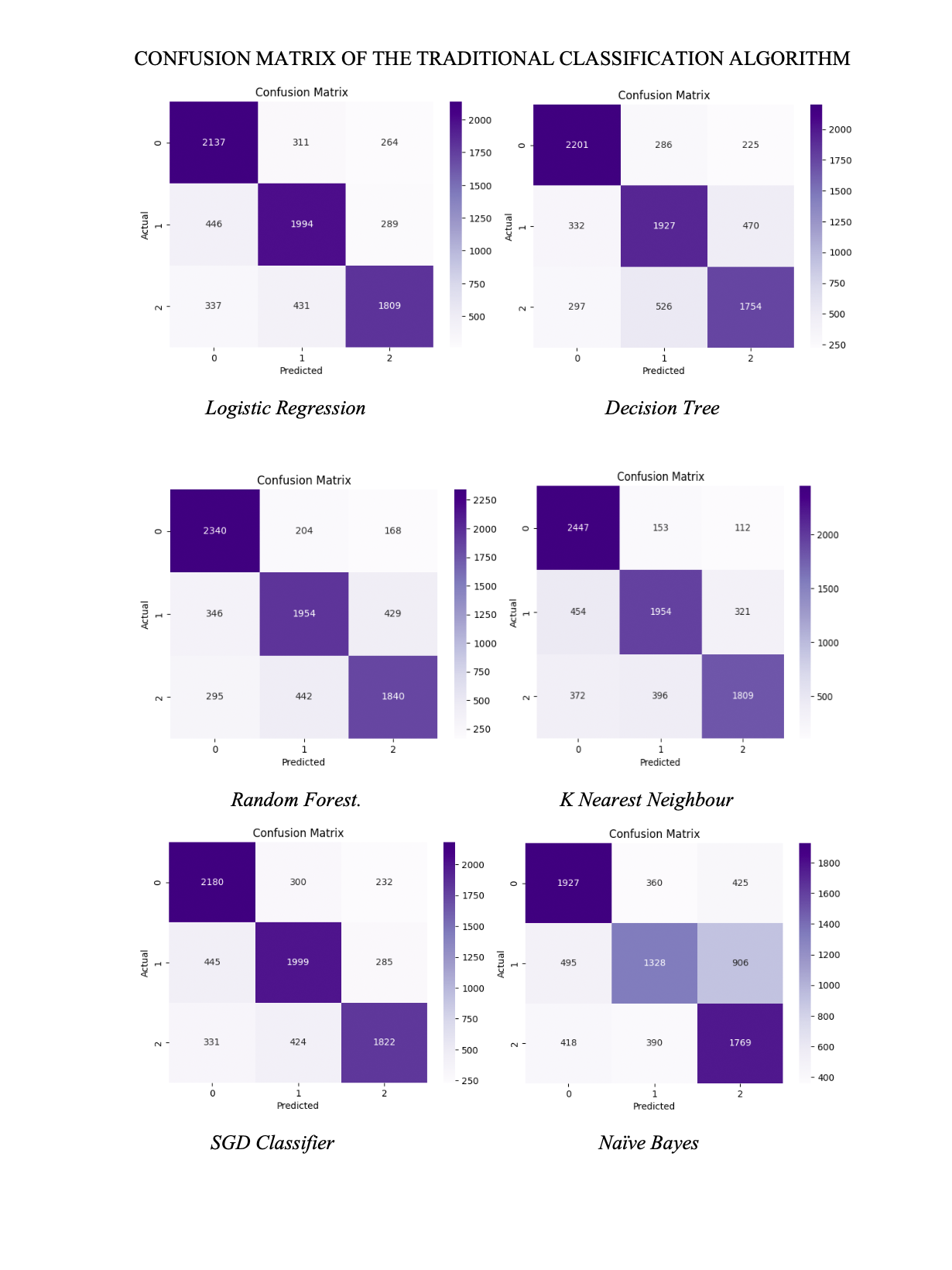
Several traditional machine learning algorithms were employed to classify accident severity into three categories: “fatal,” “serious,” and “slight.” The classification algorithms used were:
- SGD Classifier
- Logistic Regression
- Naïve Bayes
- Random Forest
- Decision Tree
- k-Nearest Neighbour
- Hyperparameters for each algorithm were optimized using grid search with cross-validation. Model performance was evaluated using confusion matrices and performance metrics, including accuracy and precision.
Classification using Neural Networks
- A multi-layer perceptron (MLP) model was created for classifying accident severity. The neural network model was optimized using a grid search over various hyperparameters, including learning rate and the number of hidden layer nodes. Model performance was evaluated using confusion matrices, performance metrics, and comparison with a trivial baseline.
Model Evaluation and Comparison
- The performance of traditional machine learning algorithms and the neural network model was compared based on their accuracy and precision. The Neural Network model achieved the highest performance metrics, with an accuracy of 0.78. The learning curve of the Neural Network model was also analyzed to further investigate its performance.
Conclusion
- The Neural Network model provided the most credible and accurate solution for determining accident severity. It outperformed traditional machine learning algorithms in terms of accuracy and precision, making it the best choice for predicting accident severity in this dataset.